
Genetik

1.0.2. HiDNA’nın Doğuşu: DNA’da Veri Depolama Teknolojisinin Dünü, Bugünü ve Yarını

Avrupa Biyoinformatik Enstitüsü'nden (EBI) Nick Goldman, 2015 Davos Dünya Ekonomik Forumu yıllık toplantısında, DNA’da bilgi depolama ve DNA kriptoloji ile ilgili bütün dünyanın ilgisini çekecek bir sürpriz yaptı. Sunumu sırasında, DNA dizileri içerisine şifrelediği Bitcoin özel anahtar şifrelerini kodladı ve DNA’ları tüplere koyarak dinleyicilere dağıttı. Her bir tüpün, DNA'da kodlanmış olan tam bir Bitcoin’in özel anahtarını içeren DNA'nın şifresini çözen ilk kişiye Bitcoin vereceğini açıkladı. Bu şifrenin çözülmesi tam üç yıl sürdü ve sonunda Sander Wuyts 2018’de bunu başararak DNA’da bilgi depolamanın ne kadar çılgınca ve güvenilir olduğunu gözler önüne serdi.
Modern dünya, her gün tsunami kadar veriyle karşı karşıya. 2013’te insanlar 4.4 zettabayt veri üretmişti; 2025'te ise 160 zettabayt ile bilgi patlaması olacağı hesaplanıyor. Bu gidişle mevcut altyapı ile 2040 yılına kadar tüm dünyadaki mikroçip dereceli silikonun tükenmesi bekleniyor. Bu nedenle, mevcut teknolojik altyapının bu veri tufanının sadece bir kısmına yetebileceği öngörülüyor. DNA işte bu dünya kadar verinin hepsini depolamanın son derece kompakt bir yolu olarak ortaya çıktı. Gezegendeki her iPhone, PC ve sunucu verileri, bir şeker küpü kadar DNA dizisinin içerisine sığdırılabilir! Aynı zamanda inanılmaz derecede de dayanıklı: DNA serin ve kuru tutulduğu sürece binlerce yıl dayanabilir. Ve son birkaç yılda, araştırmacılar A, T, C ve G harflerinden oluşan dizilerden her türlü şeyi kodlamayı başardılar: Savaş ve Barış, Deep Purple’ın “Sudaki Dumanı”, dört nala koşan bir at GIF’i. Mevcut silikon çip veya manyetik bant depolama teknolojilerinin yerine geçmek için, DNA'nın tahmin edilebilecek şekilde hızlı okunması, yazılması ve paketlenmesi her geçen yıl daha mümkün ve ucuz olacak. Müzikten uydu görüntülerine ve araştırma dosyalarına kadar çoğu dijital arşiv manyetik bantta saklanmaktan kurtulabilir! Semiconductor Research Corporation'ın sorumlu bilim insanı Victor Zhirnov, “Bugünün teknolojisi zaten ölçeklendirmenin fiziksel sınırlarına yakın,” diyor. “DNA, bilinen diğer tüm depolama teknolojilerinden daha yüksek büyüklüklerde bir bilgi depolama yoğunluğuna sahiptir.”
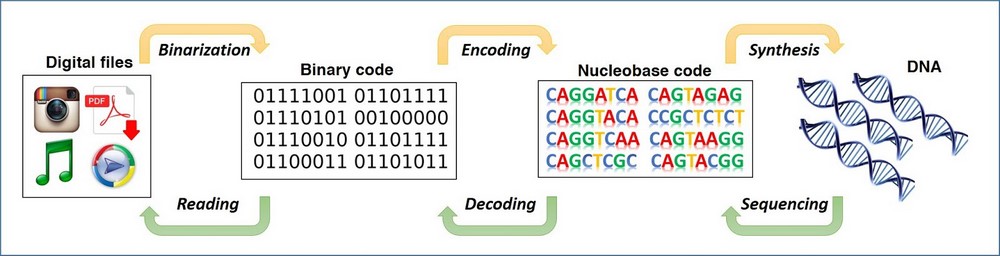
DNA’da dijital veri depolama, sentezlenmiş DNA iplikçiklerine ve bunlardan gelen ikili verilerin (1 ve 0’lar) kodlanması ve kodlarının çözülmesi işlemi olarak tanımlanmaktadır. DNA’da veri depolama, her geçen gün popüler bir konu haline gelse de, ortaya yeni atılan bir fikri değildir. Kökenleri, Sovyet fizikçi olan Mikhail Neiman'ın, Radiotehnika dergisinde çalışmalarını yayınladığı 1964-65 yıllarına kadar uzanıyor. Neiman, buradaki makalesinde, DNA moleküllerinde bilgilerin kaydedilmesi, saklanması ve geri alınmasının olasılığına dair genel düşüncelerini not düşerek, DNA’da bilgi saklamanın fizibilitesine değinen tarihteki ilk kişidir.
DNA’da veri depolamasının ilk örnekleri arasında, 2007 yılında Arizona Üniversitesi'nde bir DNA sarmalındaki uyumsuzluk alanlarını (mismatch) kodlamak için adresleme molekülleri kullanılarak bir cihaz geliştirildi. Bu uyumsuzlukların daha sonra restriksiyon enzimleri kullanarak DNA’daki verinin okunabildiği ve böylece verilerin kurtarılabildiği göszterilmiş oldu (Skinner ve ark. 2007).
16 Ağustos 2012 tarihinde ise, Science dergisinde, Harvard Üniversitesi'nden George Church ve arkadaşları DNA’da kodlanmış olan, 53 bin 400 kelimelik bir kitabın HTML taslağını, 11 JPG resminin ve bir JavaScript içeren dijital bilginin de DNA’ya kodlamayı başardıklarını gösteren ilk araştırma makalesini yayınladı. DNA'nın her santimetre küpünde 5.5 petabit bilginin saklanabildiğini gösterdiler. Bu araştırma ile ilk defa DNA'nın diğer fonksiyonlarının yanı sıra, sabit diskler ve manyetik bantlar gibi başka bir depolama ortamı olarak kullanılabileceği gösterilmiş oldu (Church ve ark. 2012).
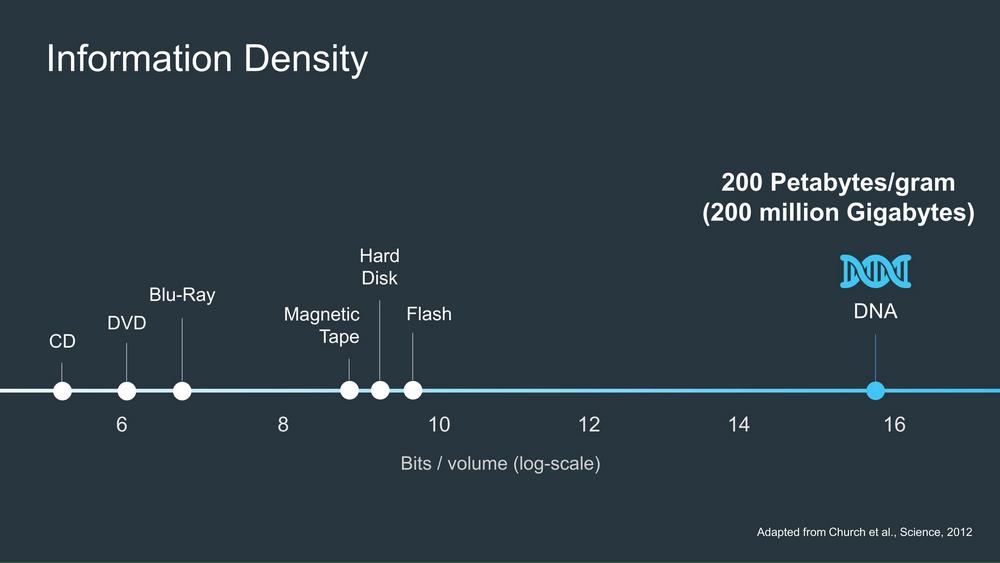
Avrupa Biyoinformatik Enstitüsü'nün (EBI) araştırmacılarının önderliğinde Nature dergisinde, Ocak 2013'te DNA’da bilgi depolama üzerine geliştirilmiş bir sistem makalesi yayınlandı. Beş milyondan fazla veri biti DNA’da saklandı ve çoğaltıldı. Tüm DNA dosyaları bilgileri %99.99-100 doğruluk oranında tekrar okunması başarıldı. 2013’te megabayt başına, verileri kodlamak için 12.400 dolar ve geri dönüş için 220 dolar olarak maliyet hesaplandı (Goldman ve ark. 2013). Bununla birlikte, yaklaşık on yıl içinde uzun vadeli veri depolama için daha uygun maliyetli hale getirileceği hiç de uzak değil. Diğer yandan, DNACloud adlı bir yazılım, Gupta ve arkadaşları tarafından, bilgisayar dosyalarını DNA temsillerine kodlamak için geliştirildi (.dnac dosyaları) (Shah ve ark 2013; Limbachiya ve ark. 2016).
ETH Zürih'ten araştırmacılar 2015’te ise DNA’nın üretildikten sonra yüzlerce yıl bozulmadan saklanabileceğini gösteren bir makale yayınladı. DNA'yı Sol-jel kimyasıyla silika cam küreleri içine yerleştirerek hava değmeden saklanabileceğini gösterdiler (Grass ve ark. 2015). 2016 yılında, 22 MB MPEG sıkıştırılmış film dizisinin depolandığı ve DNA'dan geri kazanılarak okunabildiğini, Church and Technicolor Research and Innovation tarafından yapılan bir araştırma ile dünyaya duyuruldu (Blawat ve ark. 2016). 2017 yılının Mart ayında, Columbia Üniversitesi ve New York Genom Merkezi'nden Yaniv Erlich ve Dina Zielinski, 215 petabayt yoğunlukta bilgiyi depolayabildikleri DNA Fountain olarak bilinen yeni bir yöntem yayınladılar. Bu yöntem, 2 megabayt veriyi sentezlemek için 7000 dolara ve onu okumak için başka bir 2000 dolara mal olduğu için büyük ölçekli kullanıma hazır değildi (Yong ve ark. 2017; Erlich ve ark. 2017).

Mart 2018'de, Washington Üniversitesi ve Microsoft, yaklaşık 200 MB veri depolandığını ve okunabildiğini gösteren sonuçlar yayınladı. Araştırma ayrıca DNA'da depolanan veri maddelerine rastgele erişim için bir yöntem önerdi ve değerlendirdi. (Organick ve ark. 2018; Patel ve ark. 2018). Aynı ekip Mart 2019'da, DNA'daki verileri kodlamak ve kodunu çözmek için tam otomatik bir sistem sergilediklerini açıkladı (Innovation Stories, 2019). Bu aslında DNA tabanlı bilgisayarların da üretilebileceği anlamına geliyor. DNA tabanlı bilgisayarların temelini atan bir diğer çalışma, Eurecom ve Imperial College tarafından, Ocak 2019'da yayınlandı. Bu yayında, yapılandırılmış verilerin sentetik DNA'da nasıl saklanılabildiğini gösterdi. Araştırma, sentetik DNA'da yapılandırılmış veya daha spesifik olarak ilişkisel verilerin nasıl kodlanacağını ve kimyasal işlem olarak doğrudan DNA üzerinde veri işleme işlemlerinin (SQL'e benzer) nasıl gerçekleştirileceğini gösterdi (Appuswamy ve ark. 2019; oligoarchieve, 2019).
Türkiye’nin Yerli İlk ve Tek DNA’da Veri İşleme Girişimi: HiDNA.co
Veri depolama teknoloji geliştikçe ucuzlamasına karşın, büyük verilerin depolanması ve güvenirliliği büyük masraf ve sistemler gerektirmektedir. Vücudumuzun (canlıların) temel bilgi hazinesi DNA, son yıllarda bu büyük verilerin depolanması ve on yıllarca başka masraf gerektirmeden güvenle saklanması için biyoendüstriyi şekillendirmiştir. Ülkemizde bu alandaki eksiği görerek, Acıbadem Labcell Laboratuvarında ArGe sorumlusu olarak Genetik Mühendisliği ve Tedavileri üzerine çalışan Dr. Cihan Taştan, İstanbul Medeniyet Üniversitesi Tıp Fakültesinde okuyan ve bilgisayar kodlamaları ve algoritma geliştirmelerinde hayli deneyimli olan Bedirhan Keskin ve İsmail Çağılcı ile HiDNA girişimini başlattık. HiDNA ekibi olarak, uzman olduğumuz alandaki bilgilerimizi bilgisayar algoritmalarıyla bütünleştirip, uzun yıllar saklanabilecek kişiye özel DNA veri depolama yöntemleri geliştirmekteyiz.
Gelecekte DNA veri depolamanın ve DNA tabanlı bilgisayarların geliştirilmesinde yerli bir girişim olarak öncü olmayı hedeflemekteyiz. DNA'da yazı, resim ve hesap bilgilerinin güvenle, büyük veriyi en küçük ortamda uzun yıllar saklamak üzere sadece kişiye özel DNA algoritması geliştirmekle kalmadık. Ürettiğimiz DNA'ları özel ortam koşulları gerektirmeden ve oda sıcaklığında 40 yıla kadar bozulmadan saklayabilecek kimyasal formulasyonlar ile DNA’mızı korumayı başardık. Bu süreyi yüzlerce yıla çıkarmanın yanı sıra DNA'da Veri depolamada geliştirdiğimiz algoritma ve genetik üretim saklama metotlarıyla birlikte, bu alanda kazandığımız tecrübeleri uzmanlaşma alanımız olan gen terapilerinde özel genetik dizaynlar üretmek için de kullanıp ayrıca sağlık alanında da öncü olmayı amaçlamaktayız.
HiDNA girişimi iki basamaktan oluşmakta, DNA'da veri (yazı veya görsel) depolamak isteyen kullanıcı kurmuş olduğumuz web sitemize kayıt olarak, kişiye özel DNA şifreleme algoritmasını ücretsiz elde edebilecektir. Devamında depolamak istediği veriyi DNA dizilimine web sitemiz üzerindeki algoritmamızdan çevirerek bu DNA şifresini belirli uzunluklara kadar üretilmesi için sipariş verebilecektir. Bize ulaştırılan DNA dizi siparişini, 3-4 haftalık süre içerisinde DNA üretimine çevireceğiz. Ve son olarak üreteceğimiz DNA şifresini özel kimyasal formülde saklayarak, UV ışın korumalı özel dizaynımız 3D kristal cam küp içerisinde müşterimize sertifikası ve DNA şifreleme algoritmasıyla sunacağız.
HiDNA girişimi, dünyada DNA veri depolamada alanında Türk markası olarak tek olacaktır. Bizi dünyadaki diğer yaklaşımlardan farklı kılan ise, Noter onaylı algoritmalarımız ile olan kişiye özel şifreleme metodumuz ile istenen verinin uzun yıllar hiçbir gereksinim (bilgisayar veri deposunda olduğu gibi elektrik gideri veya soğuk depolama alanı) bulunmamaktadır olmamasıdır. HiDNA girişimimiz, yakın gelecekte halka açık şekilde de satılacak olan DNA tabanlı bilgisayar sistemleri ve bankalar gibi müşteri bilgilerini uzun yıllar masrafsız saklayabilecek DNA veri depolamada alanında öncü algoritma ve DNA üretim mekanizmaları geliştiren bir kuruluş olacaktır. HiDNA.co’da yeni teknolojilere ilgi duyan ve verilerini dünyanın en küçük formuna dönüştürüp saklamak isteyen kişiler, bireysel kullanıcı hedef müşteri kitlemiz olup verilerini uzun yıllar güvenlikli ve masrafsız bir şekilde saklamak isteyen işletmeler, bankalar gibi, ise kurumsal hedef müşteri kitlemizi oluşturmaktadır. Türkiye pazarında başlayıp burada tecrübe kazandıktan sonra global olarak operasyonumuzu genişletmeyi hedeflemekteyiz.
Kaynakça:
- Skinner, Gary M.; Visscher, Koen; Mansuripur, Masud (2007). "Biocompatible Writing of Data into DNA". Journal of Bionanoscience. 1 (1): 17–21.
- Church, G. M.; Gao, Y.; Kosuri, S. (2012). "Next-Generation Digital Information Storage in DNA". Science. 337 (6102): 1628.
- Yong, E. (2013). "Synthetic double-helix faithfully stores Shakespeare's sonnets". Nature. doi:10.1038/nature.2013.12279.
- Goldman, N.; Bertone, P.; Chen, S.; Dessimoz, C.; Leproust, E. M.; Sipos, B.; Birney, E. (2013). "Towards practical, high-capacity, low-maintenance information storage in synthesized DNA". Nature. 494 (7435): 77–80.
- Shah, Shalin; Limbachiya, Dixita; Gupta, Manish K. (2013). "DNACloud: A Potential Tool for storing Big Data on DNA". arXiv:1310.6992 [cs.ET].
- Limbachiya, D.; Dhameliya, V.; Khakhar, M.; Gupta, M. K. (2016). On optimal family of codes for archival DNA storage. 2015 Seventh International Workshop on Signal Design and its Applications in Communications (IWSDA). pp. 123–127.
- Grass, R. N.; Heckel, R.; Puddu, M.; Paunescu, D.; Stark, W. J. (2015). "Robust Chemical Preservation of Digital Information on DNA in Silica with Error-Correcting Codes". Angewandte Chemie International Edition. 54 (8): 2552–5.
- Blawat, M.; Gaedke, K.; Hütter, I.; Chen, X.-M.; Turczyk, B.; Inverso, S.; Pruitt, B. W.; Church, G. M. (2016). "Forward Error Correction for DNA Data Storage". Procedia Computer Science. 80: 1011–1022.
- Yong, Ed. "This Speck of DNA Contains a Movie, a Computer Virus, and an Amazon Gift Card". The Atlantic. 2017.
- Erlich, Yaniv; Zielinski, Dina (2017). "DNA Fountain enables a robust and efficient storage architecture". Science. 355 (6328): 950–954.
- Organick, Lee; Ang, Siena Dumas; Chen, Yuan-Jyue; Lopez, Randolph; Yekhanin, Sergey; Makarychev, Konstantin; Racz, Miklos Z; Kamath, Govinda; Gopalan, Parikshit; Nguyen, Bichlien; Takahashi, Christopher N; Newman, Sharon; Parker, Hsing-Yeh; Rashtchian, Cyrus; Stewart, Kendall; Gupta, Gagan; Carlson, Robert; Mulligan, John; Carmean, Douglas; Seelig, Georg; Ceze, Luis; Strauss, Karin (2018). "Random access in large-scale DNA data storage". Nature Biotechnology. 36 (3): 242–248.
- Patel, Prachi (2018). "DNA Data Storage Gets Random Access". IEEE Spectrum: Technology, Engineering, and Science News.
- "Microsoft, UW demonstrate first fully automated DNA data storage". Innovation Stories. 2019
- Appuswamy, Raja; Lebrigand, Kevin; Barbry, Pascal; Antonini, Marc; Madderson, Oliver; Freemont, Paul; MacDonald, James; Heinis, Thomas (2019). "OligoArchive: Using DNA in the DBMS storage hierarchy" (PDF). Conference on Innovative Data Systems Research (CIDR).
- "OligoArchive Website". oligoarchive.github.io. 2019.
- Goldman, Nick; Bertone, Paul; Chen, Siyuan; Dessimoz, Christophe; LeProust, Emily M.; Sipos, Botond; Birney, Ewan (2013). "Towards practical, high-capacity, low-maintenance information storage in synthesized DNA". Nature. 494 (7435): 77–80.
- World Economic Forum (2015), Future Computing: DNA Hard Drives | Nick Goldman, 2018
- "DNA storage | European Bioinformatics Institute". www.ebi.ac.uk. 2018
- "Belgian PhD student decodes DNA and wins a Bitcoin | European Bioinformatics Institute". www.ebi.ac.uk. 2018
- "A Piece of DNA Contained the Key to 1 Bitcoin and This Guy Cracked the Code". Motherboard. 2018
- Sander Wuyts. "From DNA to bitcoin: How I won the Davos DNA-storage Bitcoin Challenge". 2018

Babaların Doğum Öncesi Alışkanlıkları Çocuklarının Metabolizmasını Sessizce Değiştirebilir
Aksolotllar Tüm Uzuvlarını Yeniden Büyütebiliyor - İnsanlar da Benzer Genler Taşıyor: DNA'mızda Gizli Süper Güç mü Var?
DNA Düzenleme Teknolojisiyle Tasarım Bebekler
Tunç Çağından Günümüze Ağız Sağlığının Genetik Evrimi: 4.000 Yıllık Dişlerden Çıkarılan Sırlar
KOKULARIN ARDINDA SAKLI ANLAMLAR
Gen Terapisi ile işitme kaybında umut verici sonuçlar
"İzlanda'da Yürütülen Genetik Araştırma, Ömrü Etkileyen Gizemli Bağlantıları Ortaya Koydu!"
Uzun Ömür İle İlgili Bir Gen Grubu Tespit Edildi
Genomik Düzenleme Teknolojilerinin Kanser Tedavileri İçin Uyarlanması
Epigenetikte Yenilik: Kanseri Anlamak ve Tedavi Etmenin Ötesinde Büyük Bir Adım Atıldı
Genetik Şifre Çözüldü: Alzheimer'ı Alt Etmenin Anahtarı Yeni Bir Genle mi Bulundu?
DNA Kapsüllerinin Depolama Gücü
Genomlardan Anlam Çıkarmak
Neden Her İnsanın Sesi Farklı Çıkıyor?
Kansere karşı genetiği değiştirilmiş domatesler üretildi
Genetiği değiştirilmiş deri hücrelerinden köpek klonlandı
Hamsterlar genetikleri değiştirilince agresifleşip saldırganlaştılar
DNA YALAN SÖYLER Mİ? PEKİ YA KİMERİZM?
Yeniden programlama ile saf kök hücreler üretmek için gereken faktörler belirlendi
Tek Bir Gen, Bir Ekosistemdeki Tür Çeşitliliğini Kontrol Eder
“Alerji yapmayan kedi" üretilmesi planlanıyor
Döllenmemiş tek bir fare yumurtasından yavrular üretildi
Tüm insanlar için bir soyağacı
54 bin yıllık kurt fosili, köpeklerin küçülmesine neden olan genetik sırrı açığa çıkardı
Bazı renkler sivrisineklerin dikkatini çekiyor
Avrupa’nın şarap üzümleri Batı Asya’dan gelmeler
Tarih öncesi insan DNA'sı bitlere ait sıvıda bulundu
Artık gen düzenleme teknolojisiyle cinsiyet belirlenebilecek
Domateslerin genetiği değiştirilerek üretilen parkinson ilacı
AVRUPA MISIR GENOMU İLK KEZ ÇÖZÜLDÜ



